MigryX modernizes SAS, Talend, Alteryx, IBM DataStage, Informatica, and Oracle ODI to Python, Snowflake, and Databricks — with +95% parsing accuracy and column-level lineage from day one.










Migration Products
Custom-built parsers for each source. Not generic AST generators. Every migration target produces explainable, auditable, production-ready code.
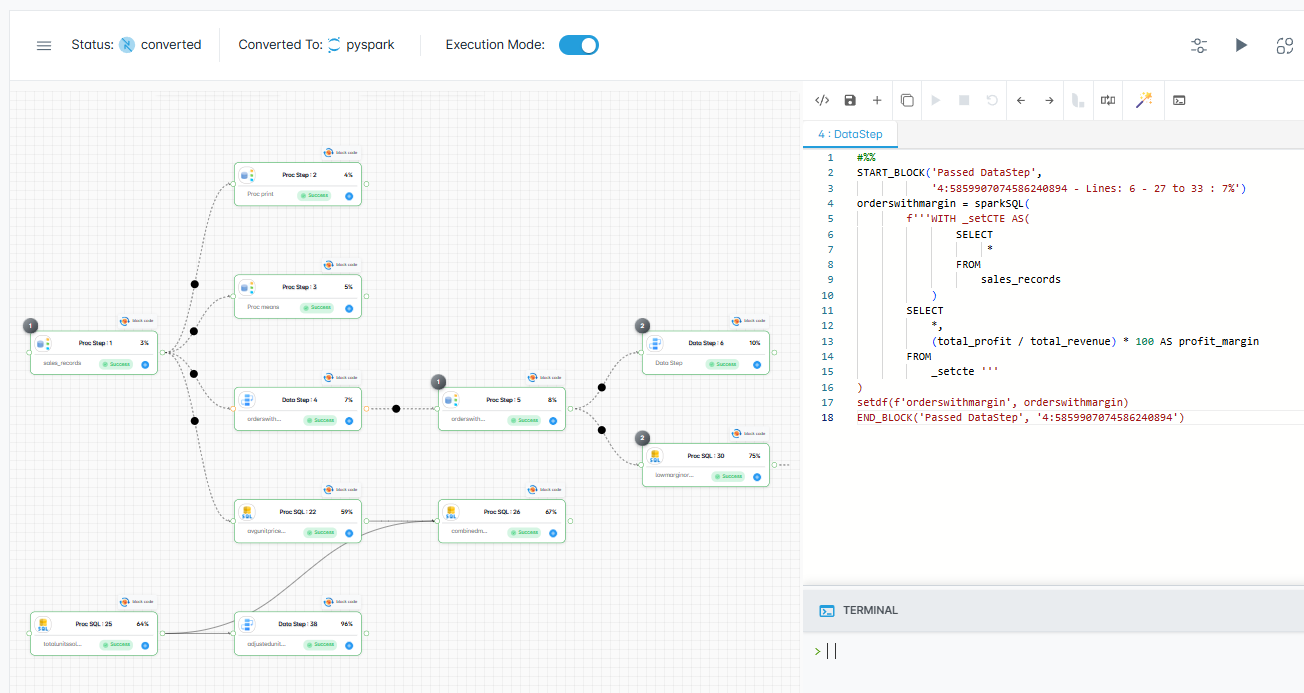
Automate SAS Base, Macro, PROC SQL, and IML conversion to Python, PySpark, Snowpark, and SQL. Full macro expansion, dependency mapping, and data validation included.
Parse Talend project exports (ZIP/Git), .item & .properties artifacts, Standard Jobs, tMap, metadata, contexts, and connections into Python, PySpark, Snowflake, and Databricks.
Convert Alteryx Designer workflows (.yxmd/.yxwz), macros, and apps to Python, PySpark, Snowpark, and SQL — with tool-level translation and full lineage preservation.
Migrate IBM DataStage parallel and server jobs, sequences, shared containers, and XML definitions to Python, PySpark, Snowflake, Databricks, and Fabric — with transformer logic preserved.
Migrate Informatica PowerCenter (.xml exports) and IDMC/IICS mappings — sources, targets, transformations, workflows, and sessions — to Python, Snowflake, Databricks, and BigQuery.
Parse Oracle ODI repository exports — mappings, interfaces, knowledge modules, packages, and load plans — and convert to Python, PySpark, Snowflake, Databricks, and Redshift.
Parse SQL Server Integration Services .dtsx packages and .ispac project archives — data flow, control flow, SSIS expressions, C#/VB.NET script tasks — to Airflow, Python, ADF, Databricks, and AWS Glue.
Migrate Oracle PL/SQL stored procedures, packages, triggers, and views with 2000+ function mappings, CONNECT BY → recursive CTE rewriting, BULK COLLECT/FORALL, and full package dependency resolution.
Migrate Teradata BTEQ scripts, FastLoad, MultiLoad, FastExport, TPump, and Teradata SQL — with QUALIFY rewriting, BTEQ command translation, PRIMARY INDEX advisory, and column-level lineage.
Migrate SAS DataFlux dfPower Studio jobs, DMS Data Jobs, Process Jobs, and Real-time Services — standardize/parse/match/validate schemes — to Python, py-recordlinkage, and Great Expectations.
Transpile SQL between 15+ dialects — Oracle, T-SQL, Teradata, DB2, Netezza, Greenplum, Hive HQL, Vertica, and more — to Snowflake, BigQuery, Databricks, Synapse, Redshift, and dbt with 500+ function mappings.
Migrate any legacy ETL or analytics platform to Databricks — generating Delta Lake tables, Medallion Architecture pipelines, Auto Loader, DLT, PySpark notebooks, and Asset Bundles with full lineage.
Migrate legacy ETL and analytics to Apache PySpark — deploy on AWS Glue, EMR, SageMaker, Azure Fabric, Google Dataproc, Databricks, Cloudera, or standalone open-source Spark clusters.
Migrate legacy ETL, SQL, and analytics to Snowflake — generating Snowpark Python, Dynamic Tables, Streams & Tasks, Snowpipe, Cortex AI integrations, and Iceberg Tables with zero-copy cloning.
Migrate legacy data platforms to Google BigQuery — generating Dataform SQLX, Dataproc PySpark, Cloud Dataflow, Cloud Composer (Airflow), BigQuery ML, Vertex AI, and BigLake pipelines.
Migrate legacy analytics and ETL to Microsoft Fabric — generating Spark notebooks, T-SQL Data Warehouse queries, Lakehouse Delta tables, Data Factory pipelines, and Power BI dataflows.
Migrate legacy data platforms to Apache Iceberg — generating PySpark+Iceberg pipelines, Trino queries, Flink jobs, schema evolution configs, and catalog integrations (Glue, Nessie, Polaris).
Migrate legacy ETL and stored procedures to dbt — generating SQL models, Jinja macros, schema tests, snapshots, seeds, sources, and dbt project scaffolding with full dependency graphs.
Migrate legacy analytics to Polars — generating LazyFrame pipelines, Polars expressions, Polars SQL, and Arrow IPC/Parquet output — up to 50x faster than pandas on a single machine.
Migrate legacy analytics to Anaconda — generating conda environments, Jupyter Notebooks, pandas/NumPy pipelines, scikit-learn workflows, and SQLAlchemy integration with the full PyData ecosystem.
Migrate legacy ETL and analytics to Informatica IDMC — generating CDI mappings, taskflows, data quality rules, mass ingestion jobs, and connections with CLAIRE AI metadata.
PyFluent is an AI-native Python development platform with built-in column-level lineage, STTM, AutoBot PySpark execution, PyFlow Parser for framework migration, and automatic documentation.
Optional domain-focused AI add-on for SAS-to-Python migration. Context-aware chat, ML-driven risk scoring, dependency analysis, DeepSights similarity intelligence, and 4-step validated conversion workflows — enhancing the core parser engine.
Technology Support
Custom-engineered parsers for 25+ technologies spanning legacy systems, databases, ETL platforms, BI tools, and modern cloud environments.
Discovery & Lineage Product
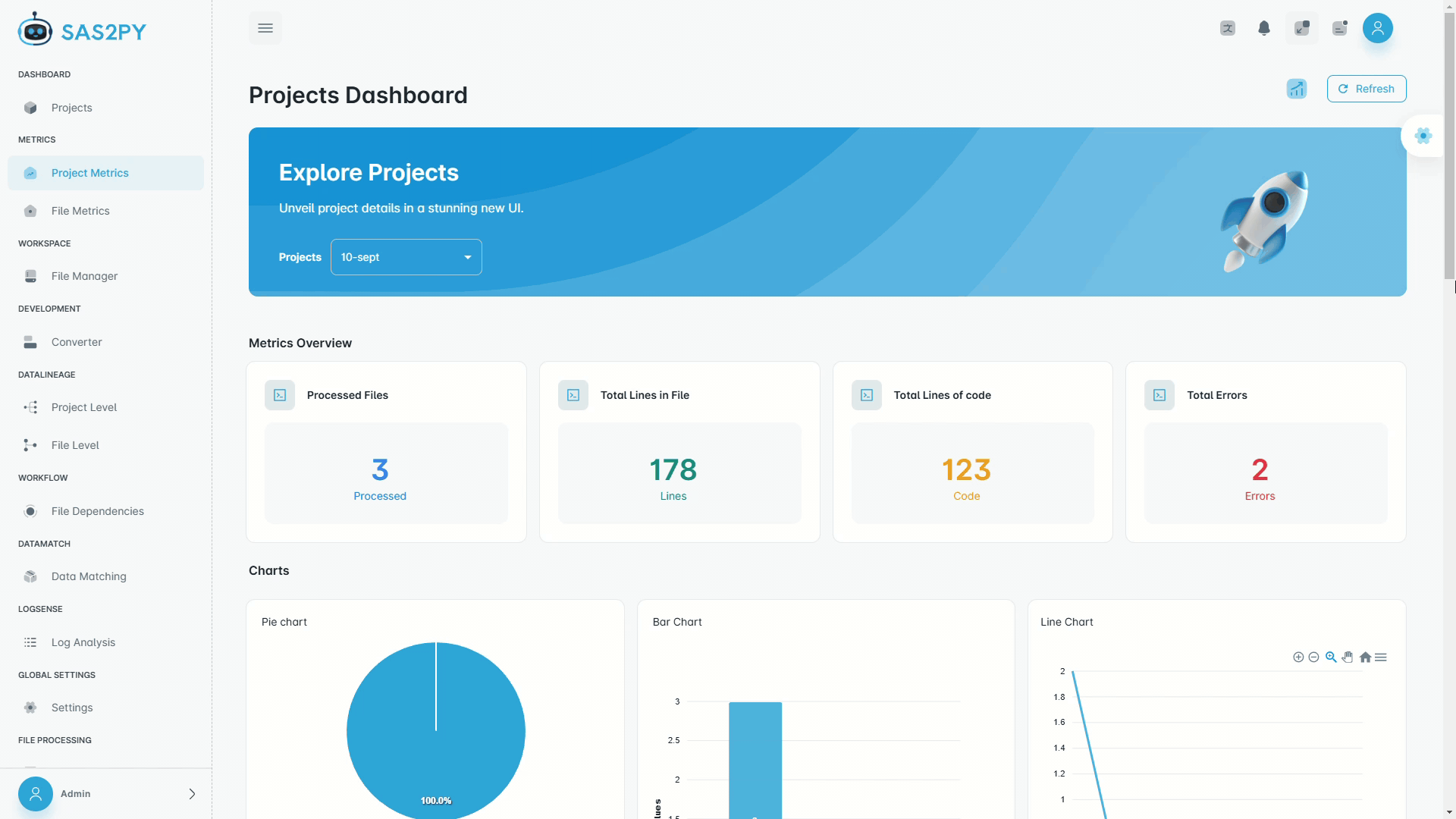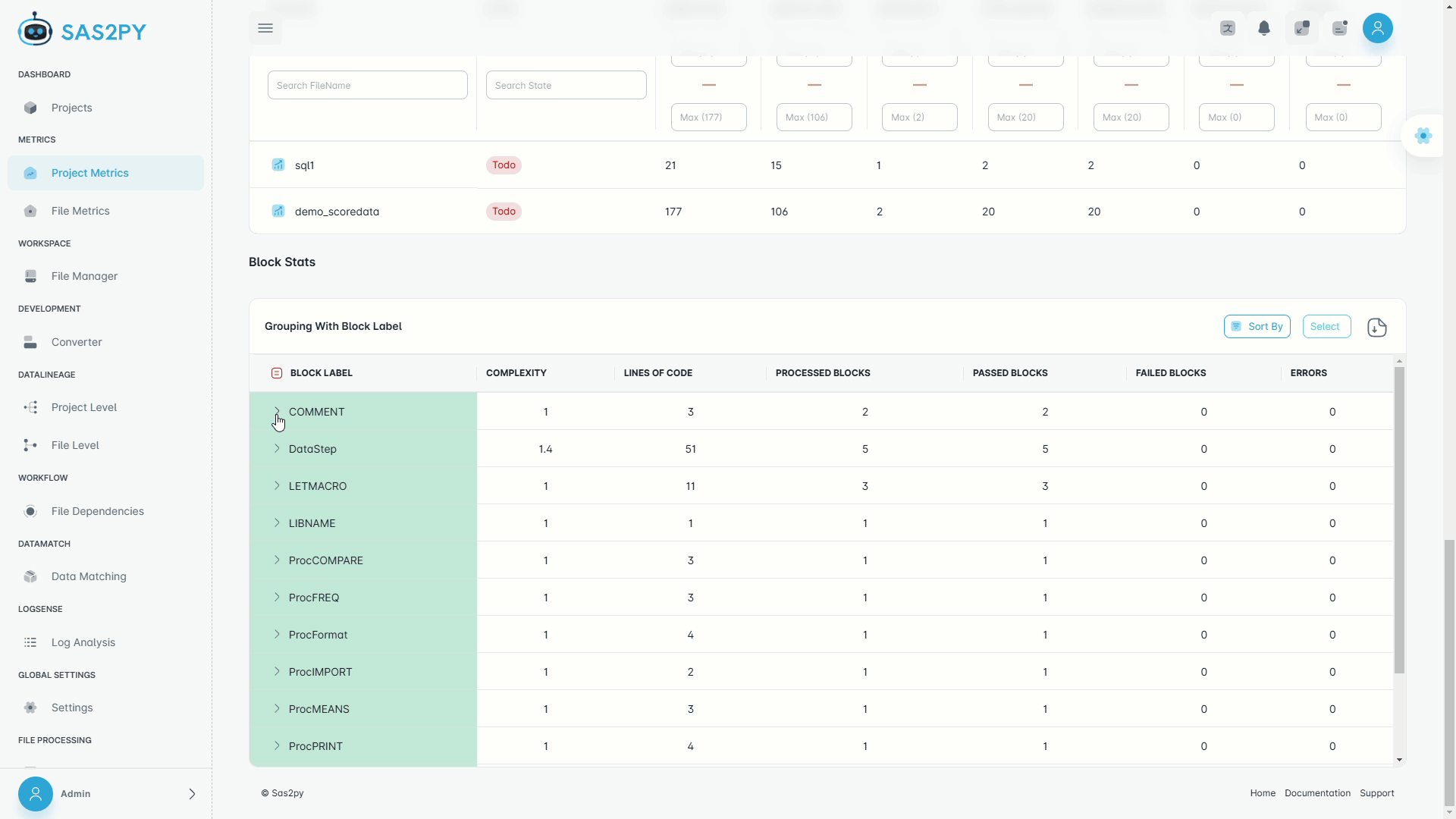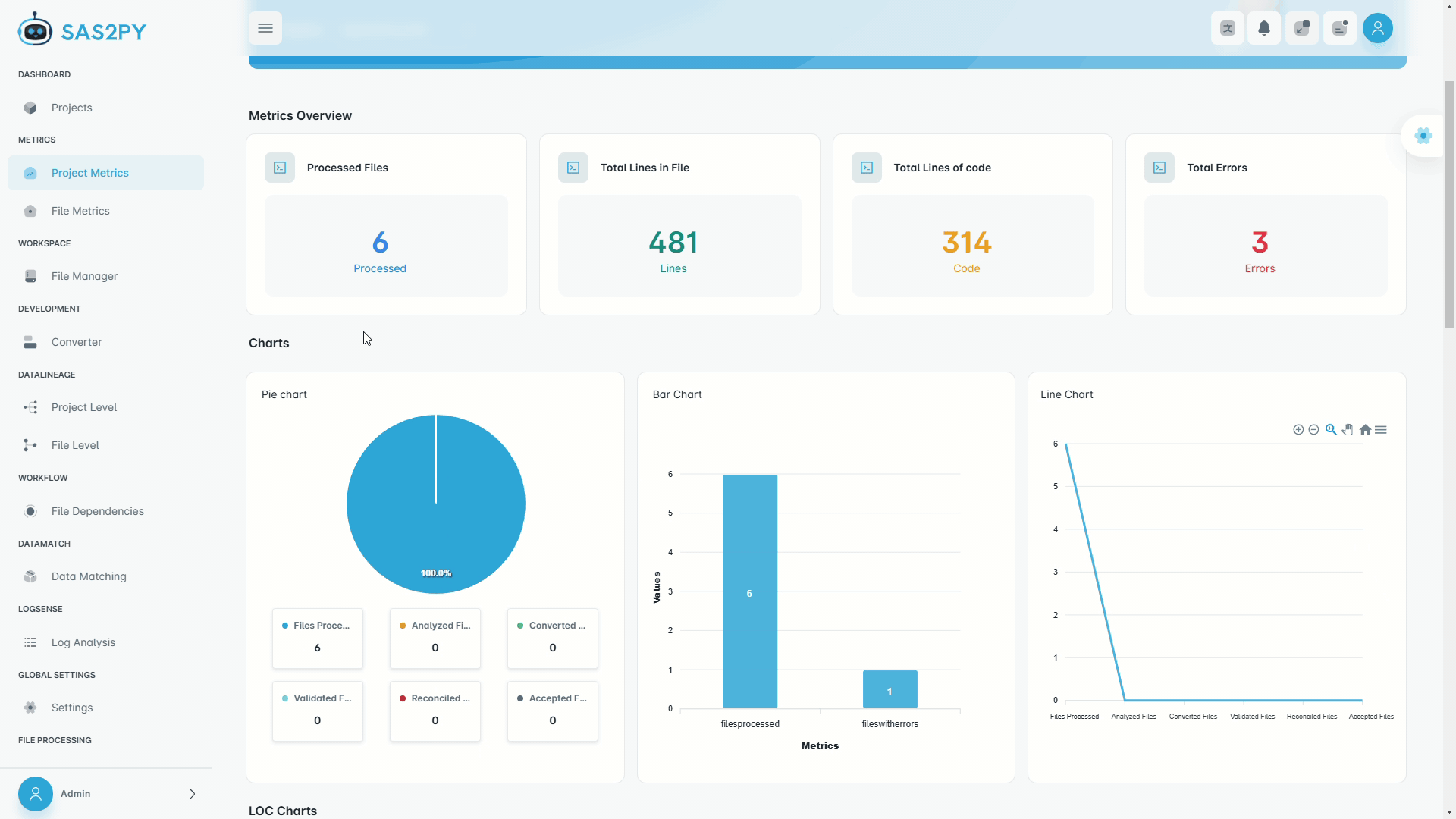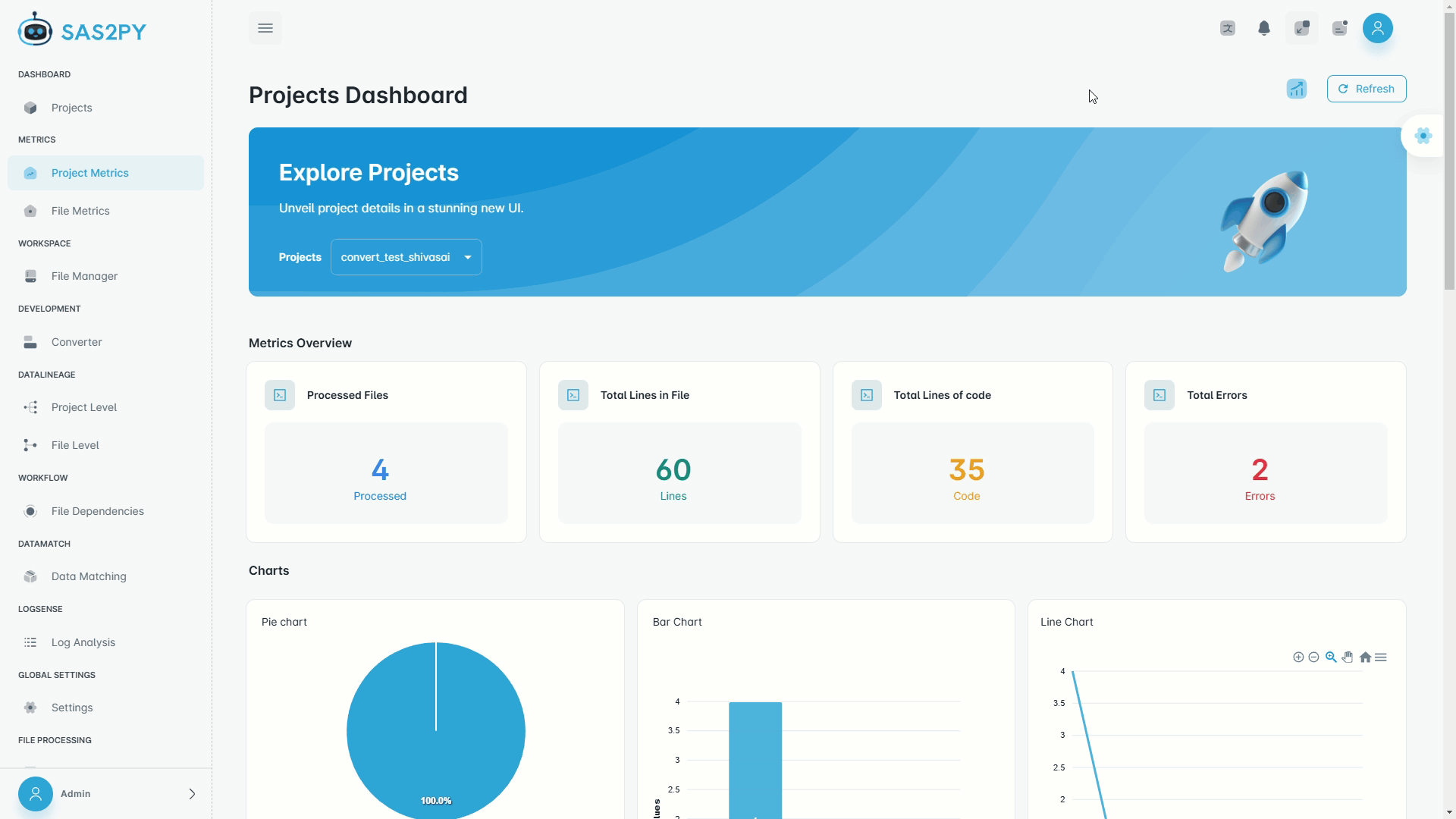
Before you migrate, you need to know what you have. MigryX Compass gives you complete visibility.
Custom-built parsers extract column-level lineage, STTM, and dependency graphs from SAS, SQL dialects, ETL tools, and 30+ languages — with zero guesswork. Optional Merlin AI analyzes the metadata to surface risk, readiness, and migration strategy.
Universal Lineage & STTM
Your data lives across dozens of tools and languages. Atlas maps it all — one unified lineage graph.
Column-level lineage and Source-to-Target Mapping across SAS, Python, PySpark, R, Polars, SQL dialects, Informatica, Talend, Alteryx, DataStage, SSIS, and every platform MigryX supports. Build new data products or modernize your entire data platform — with a complete picture of every data flow.
Shared Platform
Every MigryX product is built on the same precision parser architecture — with an optional Merlin AI intelligence layer — so lineage, analysis, and conversion are consistent across all sources.
Purpose-built for each language — not generic AST generators. Understands SAS macros, SQL vendor extensions, and ETL nuances with +95% deterministic accuracy. Up to 99% with optional AI augmentation.
Every migration produces a complete source-to-target mapping at column granularity. STTM tables, dependency graphs, and impact analysis — automatically.
Optional AI add-on that analyzes parsed metadata to surface risk, prioritize migration, detect anomalies, and generate documentation — enhancing the core parser engine with ML intelligence.
Full deployment behind your firewall with zero data leakage. Your source code, lineage, and AI analysis never leave your network. SOX, GDPR, BCBS 239 ready.
Partitioned row-level and aggregate validation compares legacy and modern outputs. Automatic schema checks, data matching reports, and exception trails for go-live confidence.
Every converted artifact gets generated documentation — data dictionaries, STTM tables, transformation logic, and dependency maps — always current, never stale.
How It Works
The same proven methodology applies to every migration — SAS, Talend, Alteryx, DataStage, Informatica, or ODI.
Scan source artifacts, build complete inventory, discover dependencies, and produce visual lineage maps.
Parser-driven conversion to Python, PySpark, Snowpark, or SQL — with matched outputs and auto documentation.
Visual orchestration on Databricks or Snowflake — step-by-step visibility, scheduling, and centralized logs.
Row-level and aggregate data matching between legacy and modern — audit-ready evidence for stakeholders.
Export lineage, STTM, and compliance reports. Merlin AI surfaces risk and recommends optimization paths.
Our Methodology
A proven, repeatable approach refined across hundreds of enterprise engagements. Every phase is automated, auditable, and built to minimize risk.
Seamless transition with dedicated support, production monitoring, and performance tuning to ensure optimal outcomes from day one.
Measurable Results
Organizations using MigryX accelerate migrations, reduce risk, and deliver proven outcomes across every modernization initiative.
Parser-driven lineage extraction — with optional AI-enhanced analysis — eliminates months of manual discovery work.
Complete visibility into dependencies prevents production incidents and migration-related defects.
Reduced consulting spend, accelerated time-to-value, and eliminated rework deliver 60%+ savings.
Deterministic custom parsers produce column-level lineage. Up to 99% with optional AI augmentation.
Automated SQL optimization delivers 20–50% query performance improvements post-migration.
Enterprise-grade SQL transpilation across 15+ dialects, eliminating manual translation errors.
Average total cost savings for large-scale modernization programs through automation and reduced rework.
From code intake to production-ready migration output — delivered in weeks with full validation.
Why MigryX
Generic ETL scanners approximate lineage. MigryX parses it exactly — every macro, every column, every dialect.
| Capability | MigryX | Generic Tools |
|---|---|---|
| Custom parser per language (not generic AST) | ✓ | ✗ |
| 100% column-level lineage accuracy | ✓ | ~ |
| SAS macro expansion & full dialect support | ✓ | ✗ |
| Talend, Alteryx, DataStage, Informatica, ODI parsers | ✓ | ~ |
| Optional AI-enhanced analysis & natural language querying | ✓ | ✗ |
| On-premise / air-gapped deployment | ✓ | ✗ |
| STTM export (CSV / JSON / Excel) | ✓ | ~ |
| Row-level data validation & parity proof | ✓ | ✗ |
| Auto-generated documentation & data dictionaries | ✓ | ✗ |
✓ Full support ~ Partial / approximate ✗ Not supported
Deployment & Security
Your source code never leaves your network. MigryX deploys entirely inside your firewall — on bare metal, VMs, or any container orchestrator — with enterprise authentication and self-service access for your teams.
Ship as OCI-compatible container images. Run on any infrastructure you already operate — no external dependencies, no data egress.
Runs in fully disconnected environments. No internet access required. All dependencies bundled in the container image.
Integrate with Active Directory, LDAP, Okta, Azure AD, or any SAML 2.0 identity provider. Role-based access control built in.
Browser-based interface for migration teams. Upload code, run conversions, explore lineage, and download results — no CLI required.
RHEL 8, RHEL 9, Amazon Linux 2023, CentOS Stream 9. Choose the OS foundation that matches your enterprise standard.
POC: 4 cores, 8 GB RAM, 20 GB disk. Production: 8 cores, 16 GB RAM, 50 GB disk. Scales horizontally on Kubernetes.
Full REST API for CI/CD integration. Automate migrations in your existing pipelines with Jenkins, GitLab CI, or GitHub Actions.
Cloud Deployment Options
Deploy on your cloud VPC with the same security posture. MigryX runs inside your account — no shared tenancy, no data leaves your environment.
Schedule a technical deep-dive on your specific source — SAS, Talend, Alteryx, DataStage, Informatica, or ODI. We'll show you parsed lineage from code.
Tell us what you would like to see in the Demo.